

MoE (395 Billones de parámetros)
NVIDIA lanza su nueva GPU H100 Tensor Core con arquitectura Hopper para ofrecer hasta 30 veces más velocidad y eficiencia que las GPUs de generación anterior.
Flytech es Elite Partner y puede ofrecer soluciones personalizadas para alcanzar el mayor potencial que nos brindan las nuevas GPUs Hopper. Además, como Partners de Supermicro desde hace más de 25 años, desde Flytech somos los primeros en España en poder ofrecer los mejores Servidores GPU NVIDIA H100 personalizados que se adapten a cualquier proyecto y empresa.
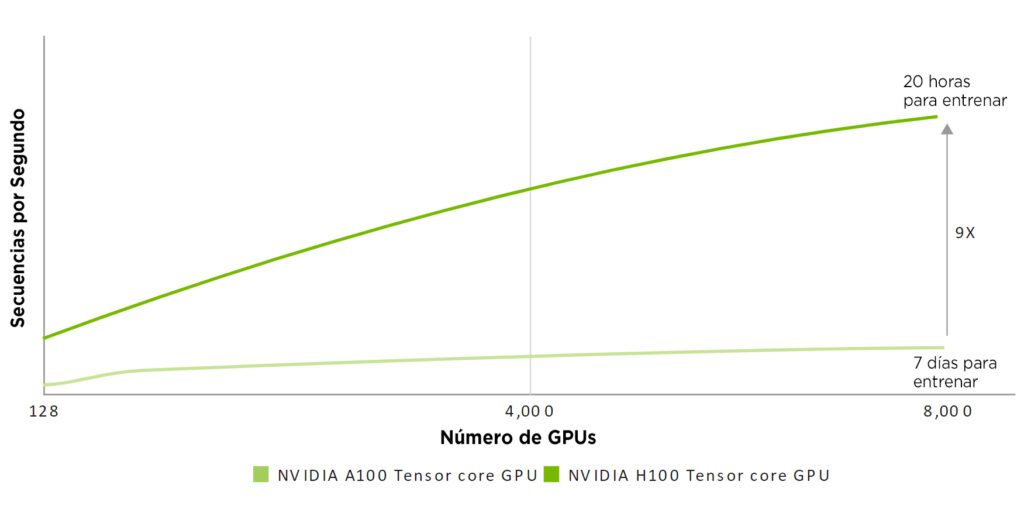
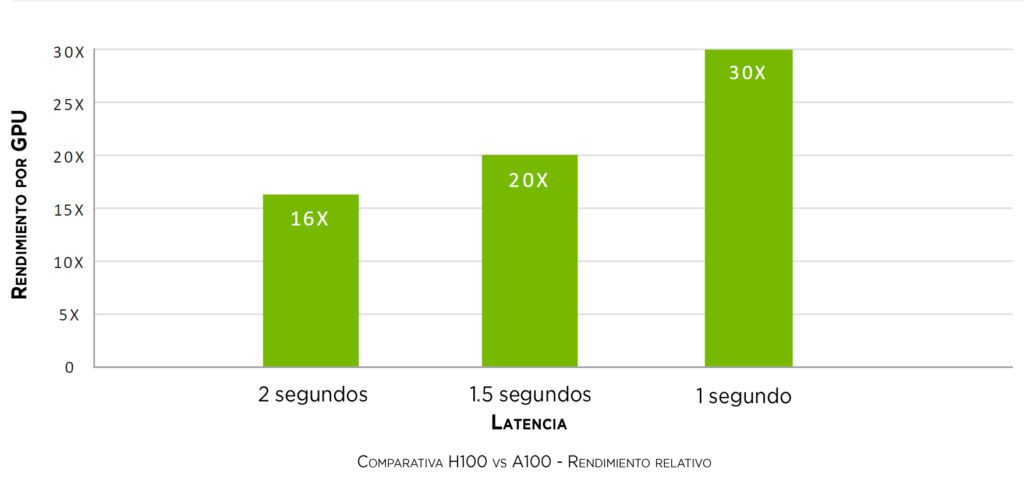 Rendimiento sujeto a cambios. Inferencia en el Chatbot del modelo de parámetros Megatron 530B para longitud de secuencia de entrada = 128, longitud de secuencia de salida = 20 | Clúster A100: red HDR IB | Clúster H100: red NDR IB para 16 configuraciones H100 | 32 A100 vs 16 H100 por 1 y 1.5 seg | 16 A100 frente a 8 H100 durante 2 segundos.
Rendimiento sujeto a cambios. Inferencia en el Chatbot del modelo de parámetros Megatron 530B para longitud de secuencia de entrada = 128, longitud de secuencia de salida = 20 | Clúster A100: red HDR IB | Clúster H100: red NDR IB para 16 configuraciones H100 | 32 A100 vs 16 H100 por 1 y 1.5 seg | 16 A100 frente a 8 H100 durante 2 segundos.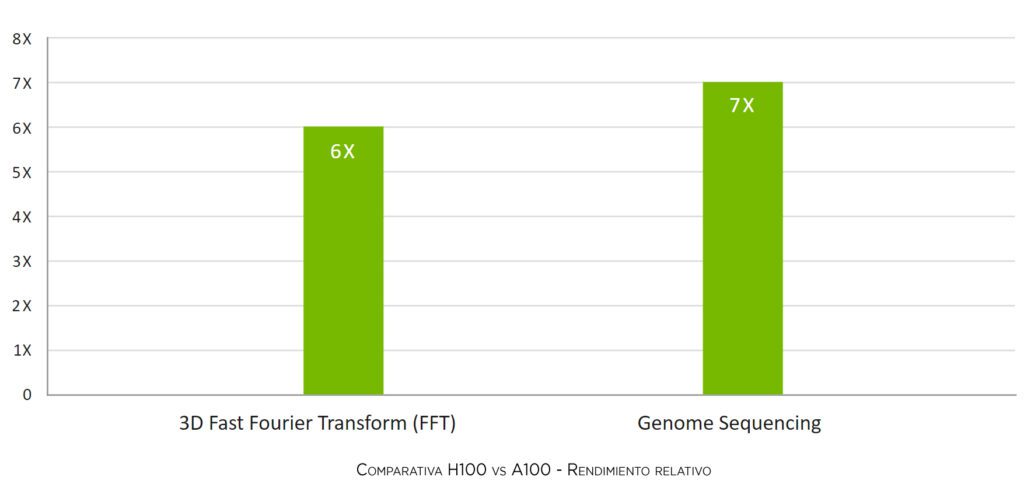 Rendimiento sujeto a cambios. Rendimiento 3D FFT (4K^3) | Clúster A100: red HDR IB | Clúster H100: Sistema de conmutación NVLink, NDR IB | Secuenciación del genoma (Smith-Waterman) | 1 A100 | 1H100
Rendimiento sujeto a cambios. Rendimiento 3D FFT (4K^3) | Clúster A100: red HDR IB | Clúster H100: Sistema de conmutación NVLink, NDR IB | Secuenciación del genoma (Smith-Waterman) | 1 A100 | 1H100






