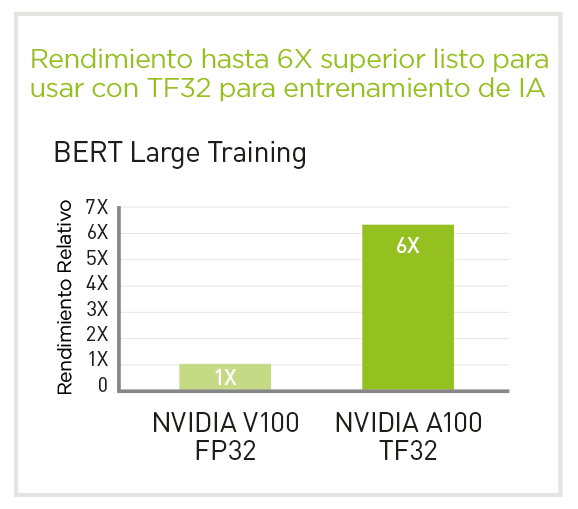
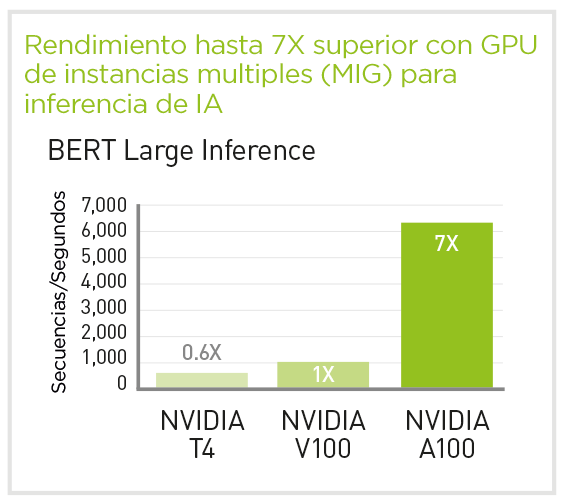
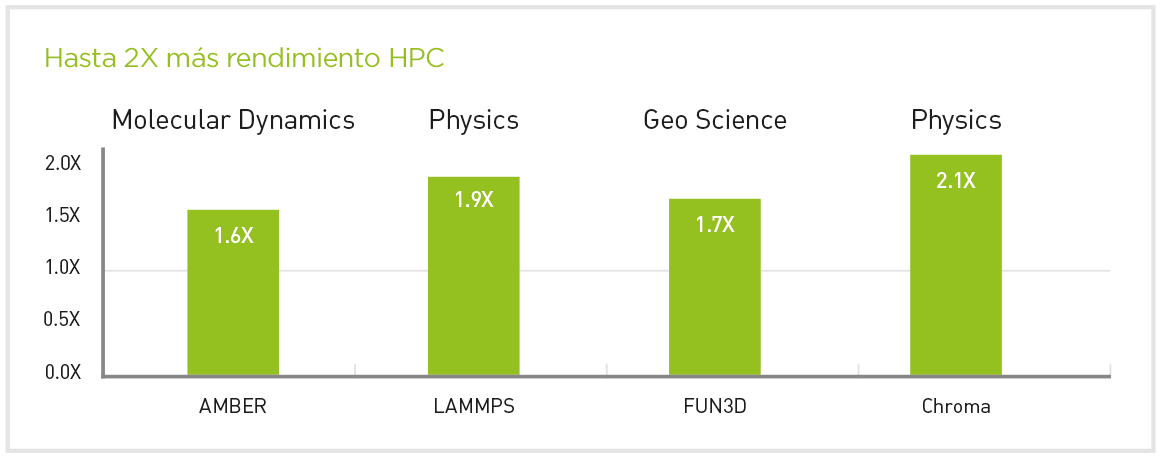
La nueva GPU A100 Tensor Core de NVIDIA proporciona una aceleración hasta ahora sin precedentes tanto para análisis de datos, como para Inteligencia Artificial (IA), como para computación de alto rendimiento (HPC) para actuar ante los desafíos informáticos más complicados del mundo.
Como motor de la plataforma de datacenter NVIDIA, la GPU A100 Tensor Core puede escalar hasta miles de GPUs o, con la tecnología NVIDIA MIG (Multi-Instance GPU), dividirse en siete instanciasd e GPU para acelerar las cargas de trabajo de cualquier tamaño.

Especificaciones
| A100 80GB PCIe |
A100 80GB SXM |
||
|---|---|---|---|
| Pico FP64 | 9,7 TF | 9,7 TF | |
| Pico de Tensor Core de FP64 | 19,5 TF | 19.5 TF | |
| Pico FP32 | 19,5 TF | 19.5 TF | |
| Pico de Tensor Core de TF32 | 156 TF | 312 TF* | 156 TF | 312 TF* | |
| Pico de Tensor Core de BFL0AT16 | 312 TF | 624 TF* | 312 TF | 624 TF* | |
| Pico de Tensor Core de FP16e | 312 TF | 624 TF* | 312 TF | 624 TF* | |
|
Pico de Tensor Core de INT8 |
624 TOPS | 1248 TOPS* | 624 TOPS | 1248 TOPS* | |
| Memoria de la GPU | 80GB HBM2e | 80GB HBM2e | |
| Ancho de banda de memoria de la GPU | 1,935 GB/s | 2,039 GB/s | |
| Interconexión | NVIDIA NVLink Bridge para 2 GPUs: 600GB/s** PCIe Gen4: 64 GB/s |
NVLin: 600 GB/s PCIe Gen4 64 GB/s |
|
| GPU de varias instancias | Hasta 7 MIG a 10GB | Hasta 7 MIG a 10GB | |
| Formato | PCIe dual-slot refrigeración por aire o single-slot refrigeración líquida | SXM | |
| Potencia máxima de TDP | 300 W | 400 W*** | |
| Opcions de servidor | Partners y Servidores certificados por NVIDIA de 1-8 GPUs | NVIDIA HGX A100 – Partner y sistemas certificados por NVIDIA con 4, 8 o 16 GPUs NVIDIA DGX A100 con 8 GPUs |
|
* Con escasez
** GPU SXM a través de placas de servidor HGX A100; GPU PCIe a través de NVLink Bridge para hasta 2 GPU
*** 400W TDP para configuración estándar. HGX A100-80GB CTS (solución térmica personalizada) puede admitir hasta 500W
GPU NVIDIA A100 para HGX

GPU NVIDIA A100 para PCIe

Especificaciones (Máximo Rendimiento)
| NVIDIA A100 SXM4 para NVIDIA HGX | NVIDIA A100 PCIe GPU | |
|---|---|---|
| Arquitectura GPU | NVIDIA Ampere | |
| Rendimiento Doble Precisión | FP64: 9.7TFLOPS FP64 TensorCore: 19.5 TFLOPS |
|
| Rendimiento Simple Precisión | FP32: 19.5 TFLOPS Tensor Float 32 (TF32): 156 TFLOPS | 312 TFLOPS* |
|
| Rendimiento Media Precisión | 312TFLOPS | 624 TFLOPS* | |
| Bfloat16 | 312TFLOPS | 624 TFLOPS* | |
| Rendimiento Entero | INT8: 624 TOPS | 1.248 TOPS* INT4: 1.248 TOPS | 2.496 TOPS* |
|
| Memoria GPU | 40 GB HBM2 | |
| Ancho de banda Memoria | 1.6 TB/sec | |
| Código de corrección de Errores | Sí | |
| Interfaz de interconexión | PCIe Gen4: 64 GB/sec Third Generation NVIDIA NVLink: 600 GB/sec** | PCIe Gen4: 64 GB/sec Third Generation NVIDIA NVLink: 600 GB/sec** |
| Factor Formato | 4/8 SXM GPUs en NVIDIA HGX A100 | PCIe |
| Multi-Instance GPU (MIG) | Hasta 7 GPU instancias | |
| Consumición de energía máxima | 400 W | 250 W |
| Rendimiento entregado para las mejores apps | 100% | 90% |
| Solución Térmica | Pasiva | |
| Compute APIs | CUDA, DirectCompute, OpenCL, OpenACC | |
* Dispersión estructural habilitada
**GPU SXM a través de placas de servidor HGX A100; GPU PCIe a través de NVLink Bridge para hasta 2 GPU
NVIDIA HGX A100
Para adaptarla a los servidores y potenciar su uso para aplicaciones de IA y HPC, la tecnología de las GPUs NVIDIA A100 Tensor Core junto con NVLink y NVSwitch han creado la plataforma NVIDIA HGX A100, una combinación ganadora.
Aprovechando la tecnología Tensor Cores de tercera generación, HGX A100 proporciona una aceleración 10 veces mayor en la IA de fábrica con Tensor Float 32 (TF32) y una aceleración 2,5 veces mayor en HPC con FP64. NVIDIA HGX A100 4-GPU ofrece casi 80 teraFLOPS de FP64 para las cargas de trabajo HPC más exigentes.
NVIDIA HGX A100 8-GPU proporciona 5 petaFLOPS de computación de aprendizaje profundo FP16, mientras que el HGX A100 de 16 vías ofrece unos asombrosos 10 petaFLOPS, lo que forma la plataforma de servidor de escalado acelerado más potente del mundo para IA y HPC.


Especificaciones
| 4-GPU | 8GPU | 16 GPU | |
|---|---|---|---|
| GPUs | 4x NVIDIA A100 | 8x NVIDIA A100 | 16x NVIDIA A100 |
| Cálculo de IA/HPC FP64/TF32*/FP16*/INT8* | 78TF/1.25PF*/2.5PF*/5POPS* | 156TF/2.5PF*/5PF*/10POPS* | 312TF/5PF*/10PF*/20POPS* |
| Memoria | 160 GB | 320 GB | 640 GB |
| NVIDIA NVLink | 3ª generación | 3ª generación | 3ª generación |
| NVIDIA NVSwitch | N/A | 2ª generación | 2ª generación |
| NVIDIA Ancho de banda de GPU a GPU de NVSwitch | N/A | 600 GB/s | 600 GB/s |
| Ancho de banda agregado total | 2,4 TB/s | 4,8 TB/s | 9,6 TB/s |